笔记-5-JavaScript高级(原型/浏览器)
JS中的函数也是对象,那么它就会有自己的属性和方法。
name属性 获取函数名称,length属性 获取形参个数(不包含剩余参数运算符和有默认值的参数)
arguments是类数组对象,虽然有length属性也可以通过index访问元素。但没有map、filter等数组才有的方法,有时候如果我们需要用到这些方法,就需要将其转为数组,可以使用ES6中的方法:Array.from()、借助展开运算符[...arguments]
老方法:[].slice.apply(arguments)
箭头函数无arguments,会去上层作用域查找
剩余参数运算符,会将没有形参接收的实参以数组形式储存起来,而arguments里面是所有的实参。剩余参数需要放在形参最后一个。
new操作会进行如下四步:
1.创建一个新对象
2.将构造函数的this绑定到这个对象
3.这个对象内部的[[prototype]]属性(一般是__proto__)会被赋值为该构造函数的prototype
4.构造函数返回该对象
函数this的绑定规则
function是“运行时上下文”策略,this是在运行时被绑定的;
默认绑定:当函数在非严格模式下独立调用时,this默认绑定到全局对象(浏览器中是window对象,在Node中是global对象),严格模式下,this是undefined。优先级最低。
隐式绑定:当函数作为对象的方法被调用时,this绑定到该对象。
显式绑定:通过call、apply、bind方法,显式指定this绑定的对象。call和apply会立即调用函数并传递this,而bind会返回一个新的函数并绑定着指定的this。优先级高于隐式绑定,bind优先级高于apply和call
new绑定:通过new关键字调用构造函数时,this绑定到新创建的对象实例。优先级高于bind,不可和call/apply使用。
初以上四种规则外,还需注意箭头函数中:
箭头函数不会创建自己的this,他会使用外部作用域的this值,通常是定义箭头函数时所在的上下文。并且是固定的不能被call等改变。
箭头函数也没有arguments属性,不能作为构造函数使用
注:IIFE、定时器、延时器默认绑定window,对象、数组调用方法时默认是对象/数组,DOM事件处理函数的this是绑定DOM的元素
call和apply的区别是call用逗号罗列参数,而apply用数组传递参数;bind绑定时入参列表,在调用时传参会排到绑定时入参的后面。
forEach等遍历方法的第一个参数是函数,默认绑定window。第二个参数就是指定绑定this
严格模式
对代码进行更严格的检测和执行,通过抛出错误来消除一些原有的静默的错误,让JS引擎在执行代码时进行更多的优化。
为了兼容早期版本,非严格模式中会有早期语言不合理的问题。
可以给某个文件开启严格模式,也可以给某个函数开启。
对象属性操作的控制
默认没有操作限制,可以将对象的某一个属性进行修改、删除等操作
如果我们想对一个属性进行比较精准的控制,可以使用属性描述符
属性描述符,需要使用Object.defineProperty来对属性进行添加或者修改
Object.defineProperty(obj,"属性",{}) // 单个监听对象的某个属性
// 一次性添加这个对象的多个属性的监听
Object.defineProperties(obj,{
属性:{
configurable、enumerable、writable、value
}
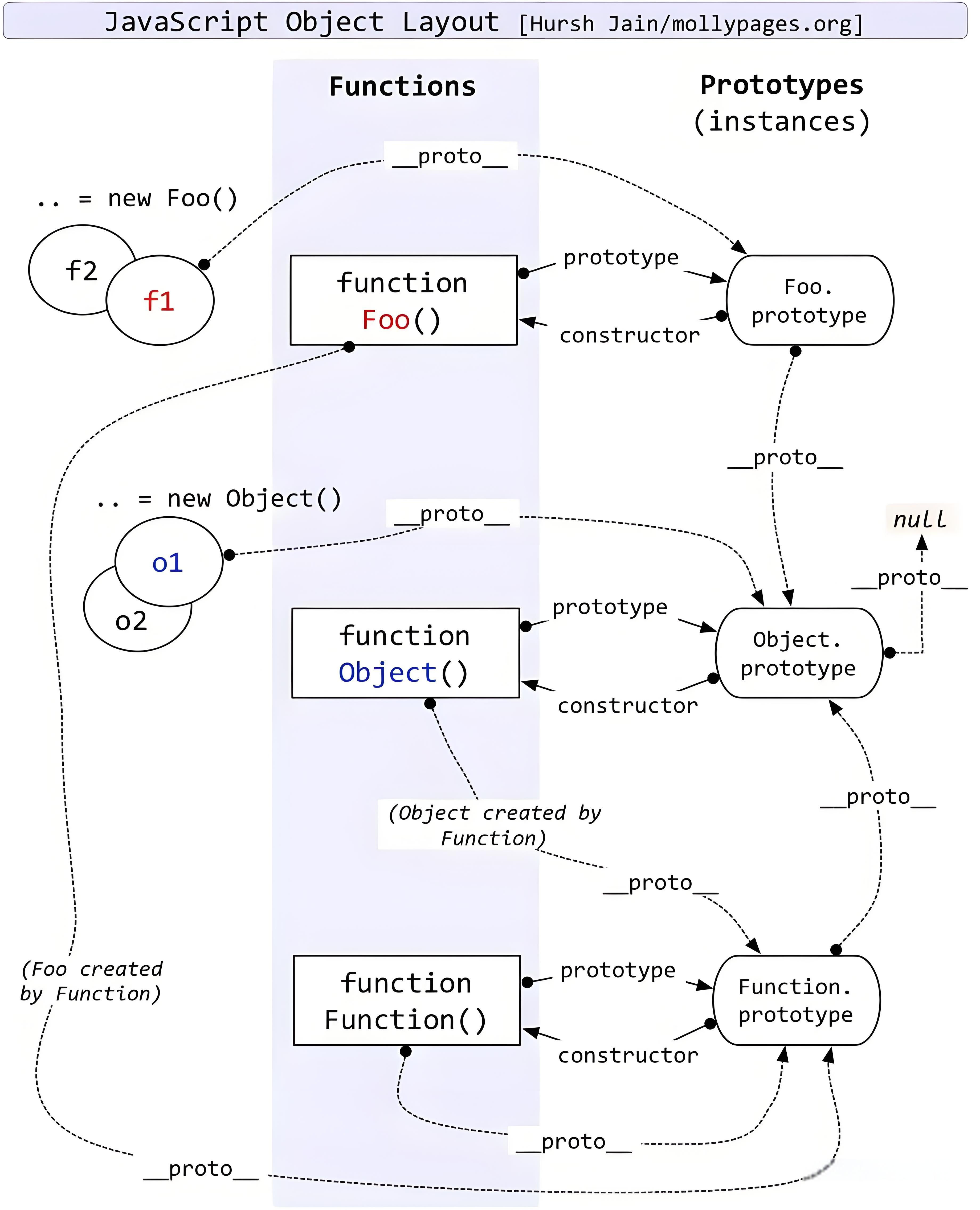
})获取普通对象的原型,obj.__proto__但这是非标准的,浏览器自己加的属性,有可能会出现兼容问题,所以尽量不要在开发中使用。正常获取需要使用Object.getPrototypeOf(obj)拿到该对象的原型
原型的作用,就是当我们在一个对象中查找某个属性时,如果它自身没有,就会去原型上查找。
将函数看作普通对象时它也是拥有隐式原型的,当将其看作函数时,它拥有显式原型prototype。它的作用是new创建对象后赋值给对象作为它的隐式原型。
原型的constructor又指向了函数自己
hasOwnProperty方法可以检查某个对象是否自己拥有某个对象或方法
in 运算符只能检查某个属性或方法是否可以被对象访问,不能检查是否是自己的属性或方法
new Date()生成当前时间的日期对象
日期对象的一些方法:
| getDate() | 得到日期 1-31 |
| getDay() | 得到星期 0-6 |
| getMonth() | 得到月份 0-11 |
| getFullYear() | 得到年份 |
| getHours() | 得到小时数 0-23 |
| getMinutes() | 得到分钟数 0-59 |
| getSeconds() | 得到秒数 0-59 |
| getTime() | 转为时间戳(精确到毫秒) |Date.parse() 将日期对象转为时间戳(精确到秒,最后三位000)
纯函数
确定的输入一定产生确定的输出,函数在执行过程中不产生副作用。
副作用:在执行一个函数时,除了返回函数值外,还产生了其他影响比如修改了全局变量。
比如数组的slice方法就是纯函数,而splice方法就不是纯函数。
柯里化
是一种关于函数的高阶技术
只传递给函数一部分参数来调用它,让它返回一个函数去处理剩余的参数,这个过程叫柯里化
组合函数
将多个函数组合,依次调用。
with语句
拓展一个语句的作用域链
eval函数
可以将传入的字符串当作JS代码执行,会将最后一句代码的执行结果作为返回值
面向对象有三大特性:封装、继承、多态
封装:将属性和方法封装到一个类中,称为封装的过程
继承:是多态的前提,可以减少重复代码的数量
多态:不同的对象在执行时表现出不同的形态
ES5中实现方法的继承,借助原型链
借用构造函数实现属性的继承
两种方式组合在一起,继承了属性和方法,叫组合继承,但也不完美。(构造函数至少被调用两次,所有子类有两份属性
function Person(name,age){
this.name = name
this.age = age
}
Person.prototype.running = function(){
console.log("running")
}
Student.prototype = new Person()
function Student(name,age,score){
Person.call(this,name,age)
this.score = score
}
最终继承方案:寄生组合式继承
目的是为了减少一次对构造方法的调用。原理上就是让一个对象的隐式原型指向父类的显式原型
// 之前不好的做法
var p = new Person()
Student.prototype = p
// 方案1
var obj = {}
// obj.__proto__ = Person.prototype 这是非标准的,存在兼容问题
Object.setPrototypeOf(obj,Person.prototype)
Student.prototype = obj
// 方案2
function F(){}
F.prototype = Person.prototype
Student.prototype = new F()比较便捷的方法:
Student.prototype = Object.create(Person.prototype)
Object.defineProperty(Student.prototype,"constructor",{
enumerable:false,
configurable:true,
writable:true,
value:Student
})
// 如果纠结Object.create的兼容性
// 手动实现一个
function createObj(o){
function F(){}
F.prototype = o
return new F()
}
// 类方法
Person.eat = function(){}原型链描述图
浏览器渲染原理
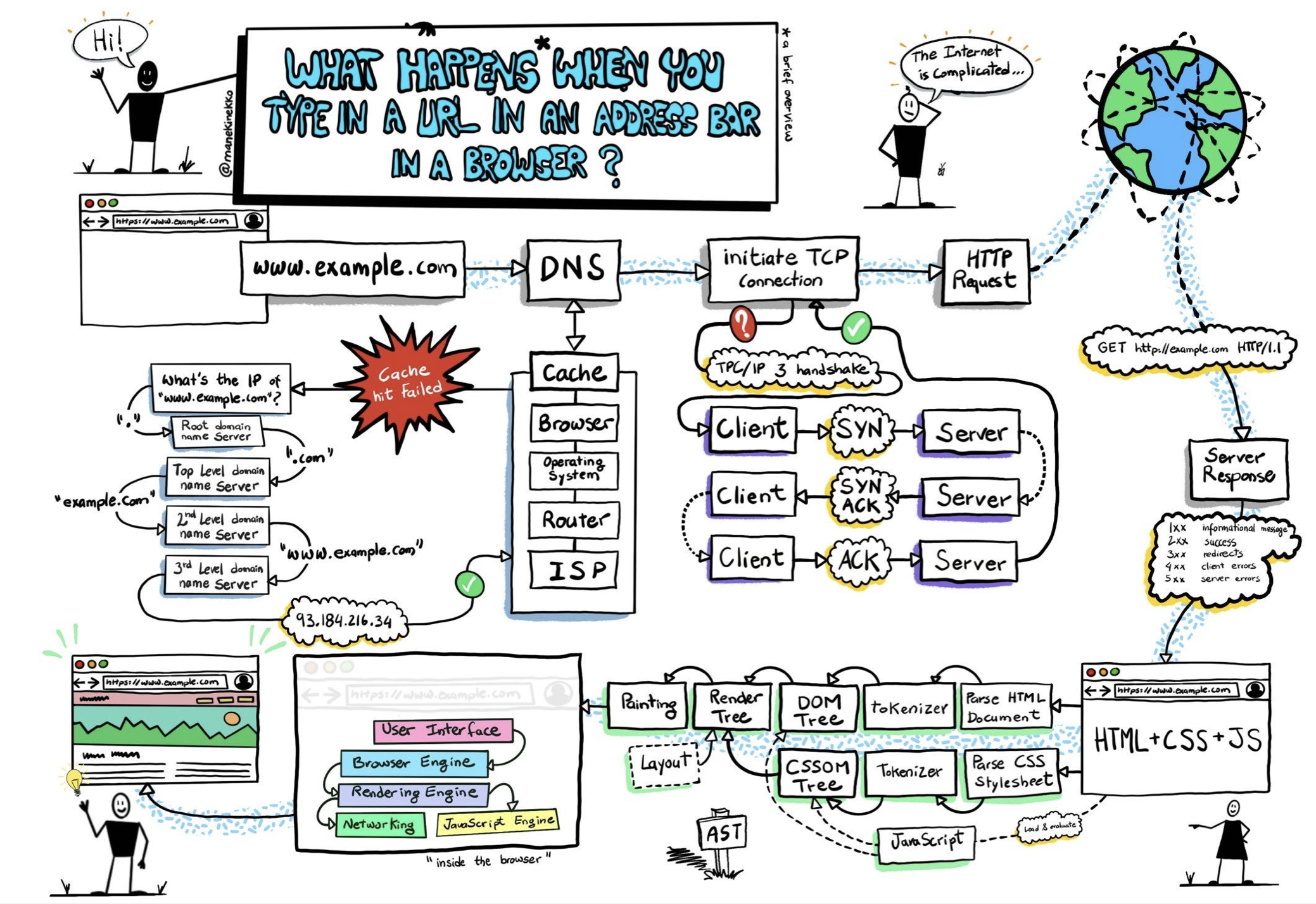
当你在浏览器的地址栏中输入了一个网址并按下回车,发生了什么?
https://dev.to/wassimchegham/ever-wondered-what-happens-when-you-type-in-a-url-in-an-address-bar-in-a-browser-3dob
第一,DNS解析:
用户输入的URL通常会是一个域名地址,直接通过域名是无法找到服务器的,因为服务器的本质上是一台拥有IP地址的主机。
需要通过DNS服务器来解析域名,并获取IP地址。
DNS会查找缓存,缓存的查找包括浏览器缓存、操作系统缓存、路由器缓存、ISP缓存,如果缓存中可以找到就可以直接使用对应IP。
如果缓存没有找到,就需要通过DNS递归解析,解析过程包括根域名服务器、顶级域名服务器、权威域名服务器。
最终找到IP地址,就通过IP地址连接服务器,并将IP地址缓存起来。
第二,TCP连接:
虽然我们发送的是HTTP请求,但HTTP协议属于应用层,是建立在TCP传输层协议之上的。
TCP的连接会经过三次握手,客户端发送SYN包,服务器接收后返回一个SYN-ACK包,客户端再次发送一个ACK包,完成握手过程。
TCP连接已建立,双方可以开始传输数据。
第三,HTTP请求:
一旦TCP建立连接成功,客户端就可以通过这个连接发送HTTP请求,包括请求方法、URI、协议版本、请求头、请求体。
服务器收到HTTP请求后,会处理这个请求,并返回一个HTTP响应。
HTTP响应包括状态码、响应头、响应内容
第四,HTML解析和CSS解析:
浏览器获取到html文件后就开始对文档进行解析,用来构建DOM Tree,在这个过程中还会遇到CSS文件和JS文件。
遇到CSS和JS的引用会继续向服务器发送HTTP请求,下载CSS、JS文件。
之后对CSS文件解析,解析出对应的CSSOM(CSS Object Model)。
第五,渲染render、布局layout、绘制paint:
DOM Tree和CSSOM可以共同构建Render Tree。
之后在Render Tree上运行布局layout计算每个结构的几何体。
再由浏览器将每个结构绘制到屏幕的像素点。
第六,composite合成:
这里还有一个优化手段,就是将元素绘制到多个合成图层中。
默认情况下,标准流中的内容是被绘制到同一个图层(Layer)中的。
可通过一些方法来创建新合成层,新图层可利用GPU加速绘制。比如3D Transforms/video/canvas/iframe/will-change/position fixed等。
分层虽然可以优化一些性能,但也是以内存管理为代价,所以还需谨慎。
这样用户最终就看到了浏览器中显示的网页,这个过程中还包含更多细节,比如重绘、回流的问题,JavaScript的执行过程、JS引擎的相关知识。
接下俩再对上面每一步展开说说:
DNS(Domain Name System)服务器解析过程:
缓存查找过程:
1.浏览器缓存:首先浏览器会检查它缓存中是否有这个域名的记录,之前访问过的网址解析结果可能会被缓存在浏览器中。
2.操作系统缓存,浏览器缓存中没有就在操作系统中寻找。
3.操作系统中也没有就会去本地网络的路由器寻找
4.路由器中也没有就去ISP(Internet service provider)寻找,它是你的互联网服务的提供商。
DNS递归解析过程:
如果在缓存的查找过程中都没有查到,那么DNS查询就变成了一个递归查询过程,涉及到多个DNS服务器。
首先DNS的查询请求会被发送到根域名服务器,根域名服务器是最高级别的DNS服务器,负责重定向到其所管理的顶级域名服务器。
顶级域名服务器(TLD):根服务器会告诉你ISP的DNS服务器去查询哪个顶级域名服务器,顶级域名服务器掌握所有例如.com域名及其对应服务器的信息。
权威域名服务器:一旦你的DNS查询到了正确的顶级域名服务器,它会进一步定向到负责example.com的权威服务器,权威服务器中有该域名对应的具体IP地址。
最终IP地址会发送到你的电脑,并且在浏览器、操作系统、路由器、ISP的DNS缓存中留存。
TCP(Transmission Control Protocol,传输控制协议),用于建立两个端点之间的可靠会话。
三次握手:
1.客户端发送一个SYN(Synchronize)包到服务器以初始化一个连接。(随机序列号)
2.服务器收到SYN包后,返回一个SYN-ACK(Synchronize-Acknowledgment)包作为响应。(也生成一个随机序列号,并将客户端的序列号+1返回,表示确认收到)
3.客户端收到服务器的SYN-ACK包后,发送一个ACK(Acknowledgment)包作为回应。这个ACK包将服务器的序列号+1,并可能包含客户端准备发送的数据开始部分,
比如HTTP请求行 GET/HTTP/1.1 和 请求头,这被称为TCP快速打开。
HTTP(Hypertext Transfer Protocol,超文本传输协议)
TCP连接建立后,客户端就通过这个通道发送一个HTTP请求到服务器,这个请求包含了方法(GET、POST等)、URI(统一资源标识符)和协议版本,以及可能包含的请求头和请求体。
服务器收到HTTP请求后,处理并返回一个HTTP响应。响应通常包括状态码、响应头、响应内容。
TCP为HTTP提供了一个可靠的通道,确保数据正确、完整的从服务器传输到客户端。
在HTML和CSS解析这一步我们先来简单介绍一下浏览器内核:
- Webkit -> Blink: Google Chrome, Edge Blink是Webkit的分支,谷歌开发
- Webkit:Safari、移动端端浏览器(Android、IOS)由苹果主导的开源内核
- Gecko:Mozilla Firefox
- Trident:IE (微软已放弃)
- Presto:Opera 后来跟谷歌一样改用Blink
我们常说的浏览器内核指的是浏览器的排版引擎:
排版引擎(layout engine)也成为浏览器引擎(browser engine)、页面渲染引擎(rendering engine)或者样板引擎。网页下载之后是通过它来解析的。
文章:浏览器的工作方式 https://web.dev/articles/howbrowserswork?hl=zh-cn
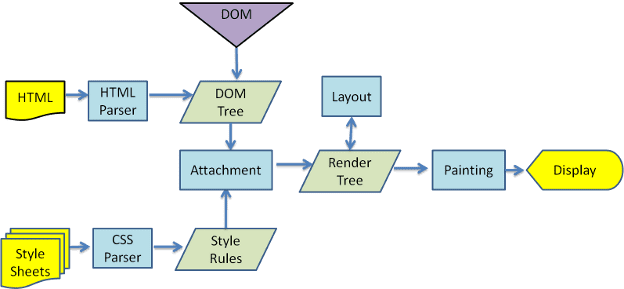
默认返回index.html文件,所以解析HTML是所有步骤的开始。
解析HTML构建DOM树,遇到link元素引入CSS文件,浏览器就会下载对应文件,下载CSS文件不会影响DOM解析。下载完后解析CSS,生成CSS规则树也可成为CSSOM。
有了DOM树和CSSOM树后,就将两个结合来构建Render Tree。
注意,link元素不阻塞DOM树的构建,但阻塞Render树的构建。Render树和DOM树不是一一对应关系,如果display为none,就不会出现在Render树。
然后,在渲染树(Render Tree)上运行布局(Layout)以计算每个节点的几何体。
渲染树会展示有哪些节点以及它的样式,但不表示每个节点的尺寸、位置信息。布局就是确定呈现树中所有节点的尺寸和位置信息。
最后,浏览器将布局阶段计算出来的每个frame转为屏幕上的像素点。(绘制,Paint)
注意:布局树是渲染树的子集,不包含渲染树中元素的颜色、背景、阴影等信息。
这里引出知识点:回流(reflow)、重绘(repaint)
回流也称重排,对节点大小、位置的修改需要重新计算。
DOM结构发生改变、改变了宽/高、padding、font-size等、窗口resize、调用getComputedStyle方法获取尺寸、位置 都会引起回流。
第一次渲染内容叫绘制,之后重新渲染叫重绘。
比如修改背景色、文字颜色、边框颜色、透明度等。
回流一定会引起重绘,所以回流非常消耗性能。在开发中要尽量避免回流。
比如:
修改样式时尽量一次性修改;
避免频繁操作DOM,可以在一个DocumentFragment或者父元素中将要操作的DOM操作完成,再进行一次性操作。现代框架常见操作,比如Vue就是这样做的。
避免通过getComputedStyle获取尺寸、位置等信息,因为浏览器需要计算。
对某些元素使用position的absolute或者fixed,脱离标准文档流,不会对其他元素造成影响。
额外:创建新的合成层(compositingLayer)
因为每个合成层都是单独渲染的
列举一些常见的属性,可创建新的合成层:
- 3D transforms
- video、canvas、iframe
- opacity 动画转换时
position:fixed- will-change:一个实验性属性,提前告诉浏览器元素可能发生哪些变化
- animation或transition设置了opacity、transform
分层可以利用GPU来获取到一些性能提升,但它以内存管理为代价,所以不能作为web性能优化策略的一部分过度使用。
下载CSS不影响DOM解析。
生成DOM Tree 和 CSSOM Tree后,两个结合构建Render Tree。
所以Render Tree 的构建也可能受CSSOM Tree的加载速度影响。
生成渲染树后会在上面运行“布局Layout”,以计算每个节点的几何体。(渲染树会表示显示哪些节点和样式,但不表示每个节点的尺寸和位置)
回流(重排):
第一次确定节点的位置和大小,称为布局(Layout),之后对节点大小、位置的修改称为回流
DOM结构发生改变(添加新节点或移除节点)、修改了布局(width、height、padding、font-size等)、修改窗口尺寸(resize)、调用getComputedStyle方法获取尺寸、位置信息,都会引发回流
重绘:
第一次渲染内容称为绘制(paint)、之后重新渲染称为重绘,修改颜色、边框样式等属于重绘
回流一定引起重绘,所以尽量避免发生回流(消耗性能)
修改样式时尽量一次性修改(比如通过class修改)
避免频繁操作dom
避免通过getComputedStyle获取尺寸、位置等信息
对某些元素使用position的absolute或fixed,并不是不引起回流,只是开销相对较小,不会对其他元素造成影响
绘制的过程,可以将布局后的元素绘制到多个合成图层中,这是浏览器的一种优化手段。
默认情况下,标准流中的内容都是被绘制在同一个图层中,而一些特殊的属性,会创建新的合成图层,并使用GPU加速绘制,因为每个合成层都是单独渲染的。
常见能够形成新合成层的属性:、
3D transforms/video/canvas/iframe/opacity动画转换时/position值为fixed/will-change/animation或transition设置了opacity、transform
分层确实可以提高性能,但它是以内存管理为代价,因此不能作为web性能优化策略过度使用
浏览器在解析HTML的过程中,遇到script元素会阻塞DOM树的构建。它会下载js代码,并且执行。执行完毕后才会继续解析HTML,构建DOM树。
这是因为JavaScript的作用之一就是操作DOM,如果等到DOM树构建完成并渲染再执行js代码,会造成严重的回流和重绘,影响页面性能。
所以遇到script元素时,优先下载并执行js代码,再继续构建DOM树
但也会带来新的问题:
在目前的开发模式中,使用Vue、React等框架,脚本往往比HTML页面更“重”,下载的时间需要很长。造成页面解析阻塞,浪费很多时间和性能。
为了解决这个问题,script提供了两个属性defer和async
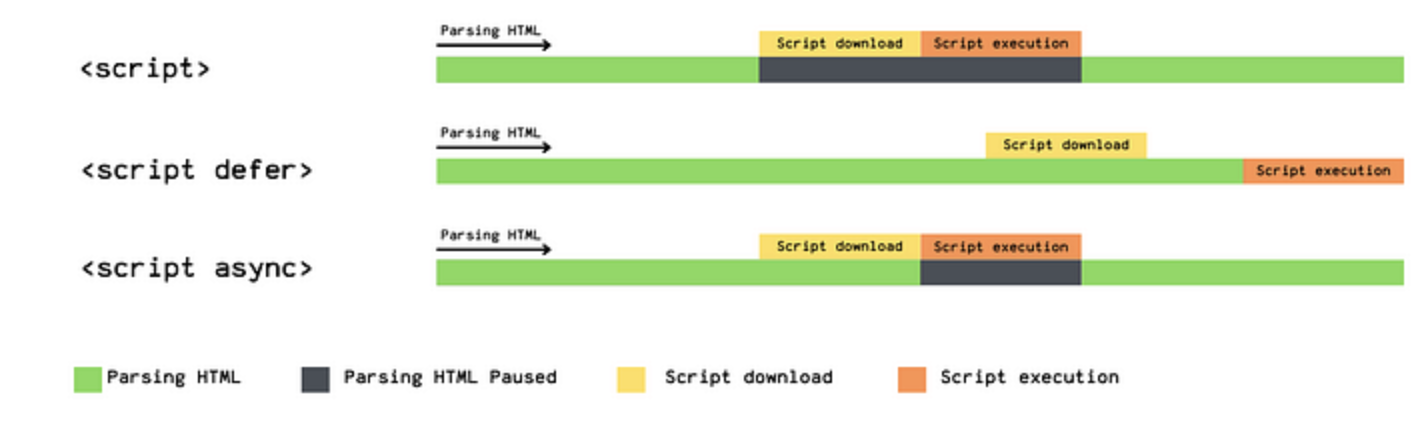
defer属性告诉浏览器不要等待脚本下载,而是继续解析HTML构建DOM Tree。
脚本由浏览器下载,下载好后会等待DOM Tree构建完成,在DOMContentLoaded事件之前执行脚本。
多个带defer的脚本是可以保持正确的顺序执行的。
所以defer可以提高页面性能,推荐放到head元素中。
async会在脚本下载完后立即执行,执行时会阻塞DOM树构建,不保证顺序,独立下载独立运行不等待其他脚本。
在现代化框架开发过程中,往往不需要手动配置async或者defer,使用webpack或者vite打包时,它会自动加上defer。
在加载一些第三方分析工具或者广告追踪脚本时可以手动加上async,对其他脚本或者dom没有依赖
注:为了达到更好的用户体验,呈现引擎会力求尽快将内容展示在屏幕上,它不必等整个HTML文档解析完毕之后再展示。