笔记-7-JavaScript高级补充(执行过程/内存管理)
JS代码下载好后,如何被一步步的执行的?
浏览器内核由两部分组成,以webkit为例:
WebCore 负责HTML解析、布局、渲染等相关操作
JavaScriptCore 负责解析、执行JS代码
JS引擎非常多,介绍几个比较重要的:
SpiderMonkey:第一款JS引擎,由Brendan Eich开发(JS作者),1996年发布
Chakra:最初是IE9的JS引擎,并在后续成为了Edge浏览器的引擎,直到Microsoft转向Chromium架构并采用V8
JavaScriptCore:是Webkit浏览器引擎的一部分,主要用于Apple的Safari浏览器,也被用在IOS设备中
V8:Chrome浏览器、Node.js的JS引擎
V8引擎是用C++编写的Google开源高性能JavaScript和 引擎,它用于Node.js和Chrome等
它实现ECMASCript和WebAssembly,并在Windows7或更高版本,macOS10.12+和使用x64,IA-32,ARM或MIPS处理器的Linux系统上运行
V8可以独立运行,也可以嵌入到任何C++程序中
V8执行JS代码的过程:
源代码先解析,转化成AST(抽象语法树),然后交给Ignition(解释器),解释器输出字节码(bytecode),同时Ignition也是能够运行字节码的(转成机器码),运行字节码后输出结果。在Ignition转换或者运行的时候就会搜集字节码的信息,由TurboFan将一些字节码转换成优化后的机器码,这样再运行这段代码的时候就可以直接使用优化后的机器码(MachineCode)无需再转换。
1.解析 (Parse):JavaScript 代码⾸先被解析器处理,转化为抽象语法树(AST)。这是代码编译的初步阶段,主要转换代码结构为内部可进⼀步处理的格式。
2.AST:抽象语法树(AST)是源代码的树形表示,⽤于表示程序结构。之后,AST 会被进⼀步编译成字节码。
3.Ignition:Ignition 是 V8 的解释器,它将 AST 转换为字节码。字节码是⼀种低级的、⽐机器码更抽象的代码,它可以快速执⾏,但⽐直接的机器码慢。
4.字节码(Bytecode):字节码是介于源代码和机器码之间的中间表示,它为后续的优化和执⾏提供了⼀种更标准化的形式。字节码是由 Ignition ⽣成,可被直接解释执⾏,同时也是优化编译器 TurboFan 的输⼊。
5.TurboFan:TurboFan 是 V8 的优化编译器,它接收从 Ignition ⽣成的字节码并进⾏进⼀步优化。⽐如如果⼀个函数被多次调⽤,那么就会被标记为热点函数,那么就会经过TurboFan转换成优化的机器码,提⾼代码的执⾏性能。当然还会包括很多其他的优化⼿段,如内联替换(Inlining)、死代码消除(Dead Code Elimination)和循环展开(Loop Unrolling)等,以提⾼代码执⾏效率。
6.机器码:经过 TurboFan 处理后,字节码被编译成机器码,即直接运⾏在计算机硬件上的低级代码。这⼀步是将JavaScript 代码转换成 CPU 可直接执⾏的指令,⼤⼤提⾼了执⾏速度。
7.运⾏时优化:在代码执⾏过程中,V8 引擎会持续监控代码的执⾏情况。如果发现之前做的优化不再有效或者有更优的执⾏路径,它会触发去优化(Deoptimization)。去优化是指将已优化的代码退回到优化较少的状态,然后新编译以适应新的运⾏情况。
V8引擎主要包含哪些部件?它们的作用是什么?
- Parse模块会将JS代码转换成AST(抽象语法树),这是因为解释器并不直接认识JS代码,如果函数没有被调用,那么是不会被转换成AST的。
- Ignition 是一个解释器,会将AST转换成ByteCode(字节码),同时会收集TurboFan优化所需要的信息(比如函数参数的类型信息,有了类型才能进行真实的运算),如果函数只调用一次,Ignition会解释执行ByteCode
- TurboFan是一个编译器,可以将字节码编译为CPU可以直接执行的机器码如果一个函数被多次调用,那么就会被标记热点函数,就会经过TurboFan转换成优化的机器码,提高代码的执行性能。但是机器码实际上也会被还原成字节码,这是因为如果后续执行函数的过程中类型发生了变化(比如入参由number类型变成了string类型),之前优化的机器码并不能正确的处理运算,就会逆向转换成字节码。所以说TS在一定程度上也能优化我们的性能.
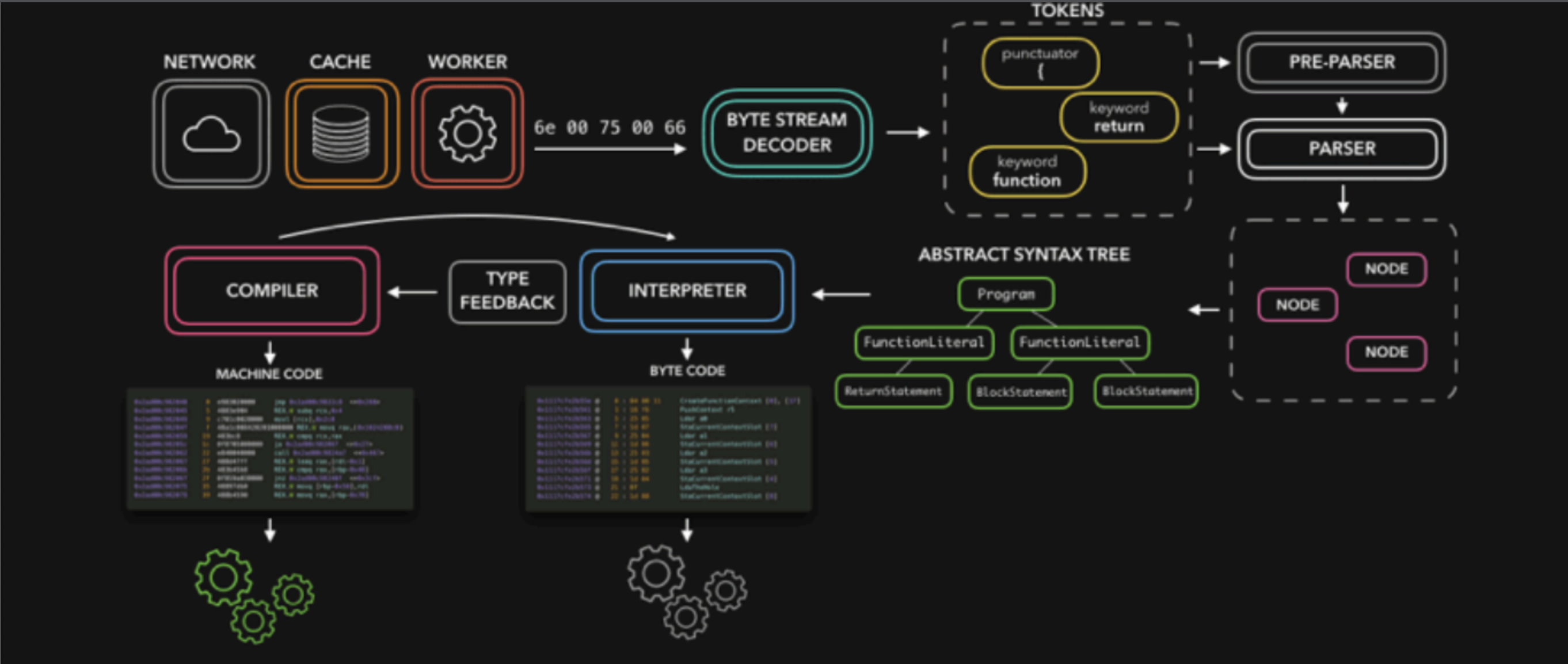
官方解析图,来自https://v8.dev/blog/scanner

那么我们的JavaScript源码是如何被解析(Parse过程)的呢?
Blink将源码交给V8引擎,Stream获取到源码并且进⾏编码转换;
Scanner会进⾏词法分析(lexical analysis),词法分析会将代码转换成tokens(记号化);
接下来tokens会被转换成AST树,经过Parser(语法分析器)和PreParser:
Parser就是直接将tokens转成AST树架构;
PreParser称之为预解析,为什么需要预解析呢?
预解析⼀⽅⾯的作⽤是快速检查⼀下是否有语法错误,另⼀⽅⾯也可以进⾏代码优化。
这是因为并不是所有的JavaScript代码,在⼀开始时就会被执⾏。那么对所有的JavaScript代码进⾏解析,必然会影响⽹⻚的运⾏效率;
所以V8引擎就实现了Lazy Parsing(延迟解析)的⽅案,它的作⽤是将不必要的函数进⾏预解析,
也就是只解析暂时需要的内容,⽽对函数的全解析是在函数被调⽤时才会进⾏;
⽐如我们在⼀个函数outer内部定义了另外⼀个函数inner,那么inner函数就会进⾏预解析;
⽣成AST树后,会被Ignition转成字节码(bytecode)并且可以执⾏字节码,之后的过程就是代码
的执⾏过程(后续会详细分析)。
内存管理
JS对于原始数据类型内存的分配会在执行时,直接在栈空间进行分配;
JS对于复杂数据类型内存的分配会在堆内存中,开辟一块空间,并且将这块空间的指针返回值变量引用
因为内存的⼤⼩是有限的,所以当内存不再需要的时候,我们需要对其进⾏释放,以便腾出更多的内存空间。
在⼿动管理内存的语⾔中,我们需要通过⼀些⽅式⾃⼰来释放不再需要的内存,⽐如free函数:
但是这种管理的⽅式其实⾮常的低效,影响我们编写逻辑的代码的效率;
并且这种⽅式对开发者的要求也很⾼,并且⼀不⼩⼼就会产⽣内存泄露(memory leaks),指针(dangling pointers);
所以⼤部分现代的编程语⾔都是有⾃⼰的垃圾回收机制:
垃圾回收的英⽂是Garbage Collection,简称GC;
对于那些不再使⽤的对象,我们都称之为是垃圾,它需要被回收,以释放更多的内存空间;
⽽我们的语⾔运⾏环境,⽐如Java的运⾏环境JVM,JavaScript的运⾏环境js引擎都会内存 垃圾回收器;
垃圾回收器我们也会简称为GC,所以在很多地⽅你看到GC其实指的是垃圾回收器;
⾃动垃圾回收提⾼了开发效率,使开发者可以更多地关注业务逻辑的实现⽽⾮内存管理的细节。
这在管理复杂数据结构和⼤数据时⾮常重要。
但是这⾥⼜出现了另外⼀个很关键的问题:GC怎么知道哪些对象是不再使⽤的呢?
这⾥就要⽤到GC的实现以及对应的算法;
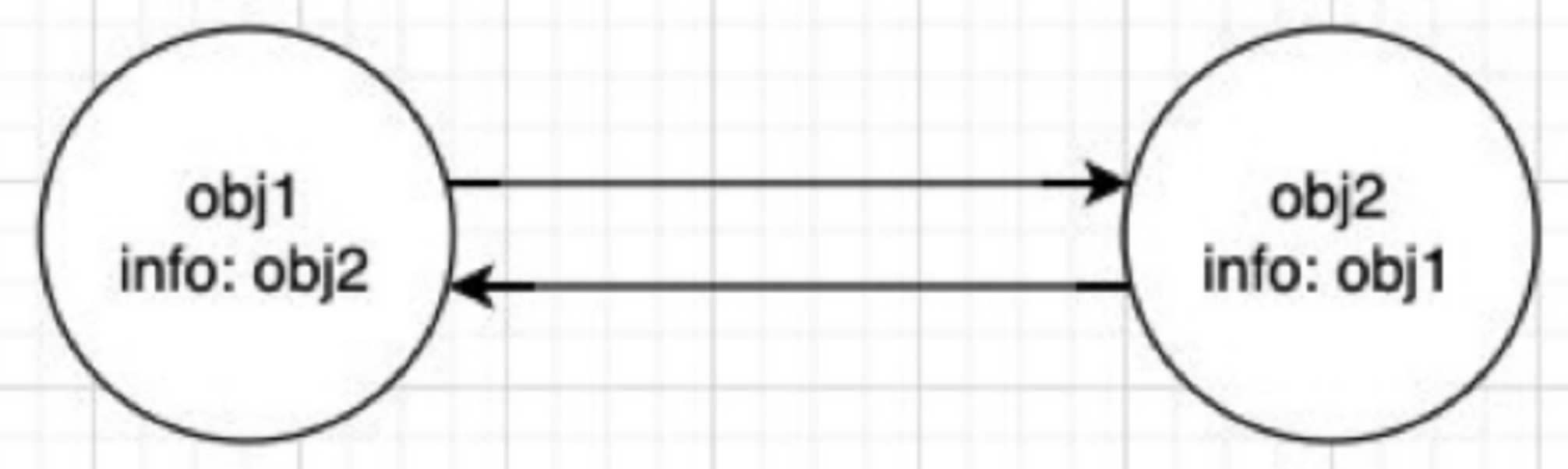
常⻅的GC算法 – 引⽤计数(Reference counting)
引⽤计数垃圾回收(Reference Counting):
每个对象都有⼀个关联的计数器,通常称为“引⽤计数”。
当⼀个对象有⼀个引⽤指向它时,那么这个对象的引⽤就+1;
如果另⼀个变量也开始引⽤该对象,引⽤计数加1;如果⼀个变量停⽌引⽤该对象,引⽤计数减1。
当⼀个对象的引⽤为0时,这个对象就可以被销毁掉;
这个算法有⼀个很⼤的弊端就是会产⽣循环引⽤,当然我们可以通过⼀些⽅案,⽐如弱引⽤来解决(WeakMap就
是弱引⽤);
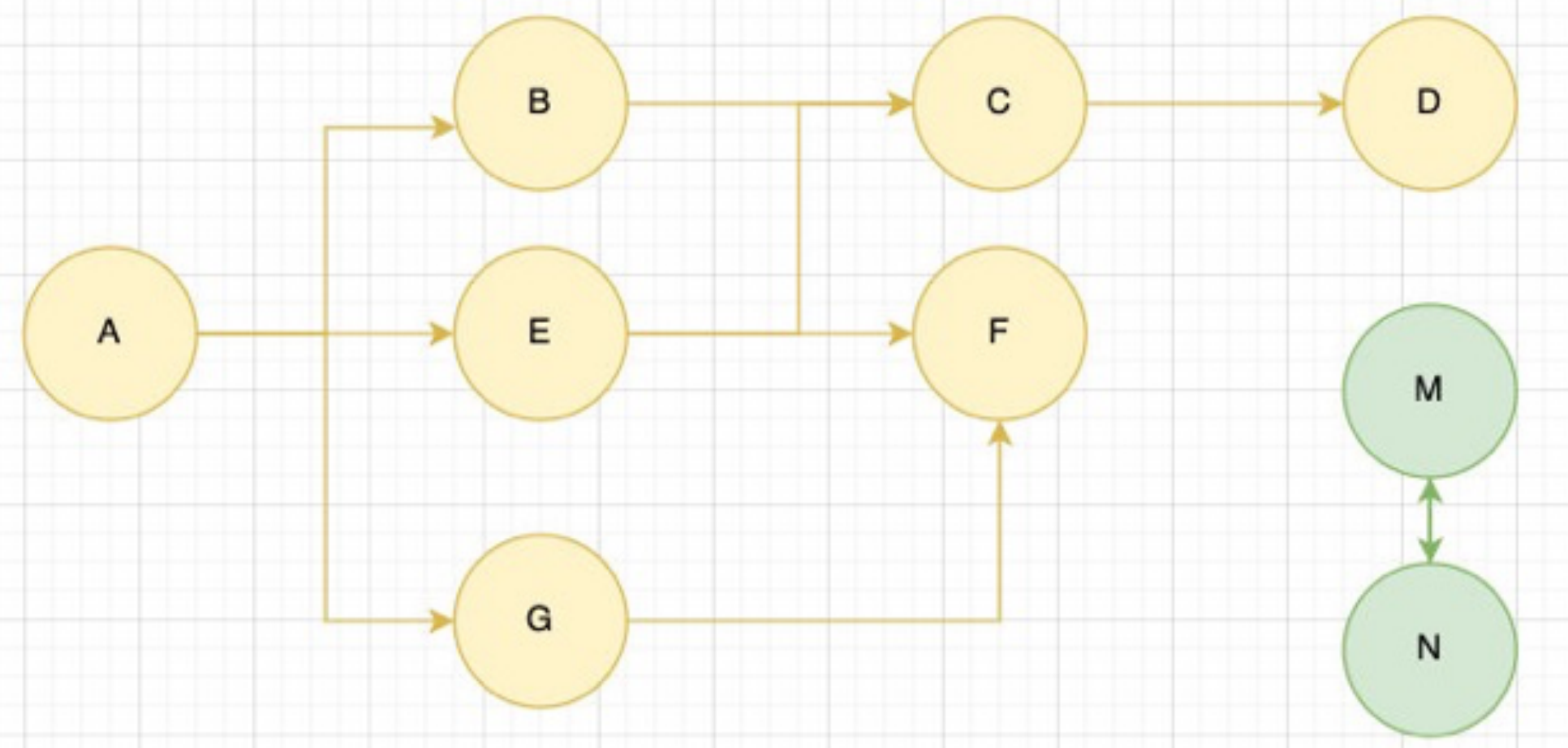
常⻅的GC算法 – 标记清除(mark-Sweep)
标记清除:
标记清除的核⼼思路是可达性(Reachability)
这个算法是设置⼀个根对象(root object),垃圾回收器会定期从这个根开始,找所有从根开始有引⽤到的对象,对于哪些没有引⽤到的对象,就认为是不可⽤的对象;
在这个阶段,垃圾回收器标记所有可达的对象,之后,垃圾回收器遍历所有的对象,收集那些在标记阶段未被标记为可达的对象。
这些对象被视为垃圾,因它们不再被程序中的其他活跃对象或根对象所引⽤。
这个算法可以很好的解决循环引⽤的问题;
JS引擎⽐较⼴泛的采⽤的就是可达性中的标记清除算法,当然类似于V8引擎为了进⾏更好的优化,它在算法的实现细节上也会结合⼀些其他的算法。
标记整理(Mark-Compact) 和“标记-清除”相似;
不同的是,回收期间同时会将保留的存储对象搬运汇集到连续的内存空间,从⽽整合空闲空间,避免内存碎⽚化;
分代收集(Generational collection)—— 对象被分成两组:“新的”和“旧的”。
许多对象出现,完成它们的⼯作并很快死去,它们可以很快被清理;
那些⻓期存活的对象会变得“⽼旧”,⽽且被检查的频次也会减少;
增量收集(Incremental collection)
如果有许多对象,并且我们试图⼀次遍历并标记整个对象集,则可能需要⼀些时间,并在执⾏过程中带来明显的延迟。
所以引擎试图将垃圾收集⼯作分成⼏部分来做,然后将这⼏部分会逐⼀进⾏处理,这样会有许多微⼩的延迟⽽不是⼀个⼤的延迟;
闲时收集(Idle-time collection)
垃圾收集器只会在 CPU 空闲时尝试运⾏,以减少可能对代码执⾏的影响。
事实上,V8引擎为了提供内存的管理效率,对内存进⾏⾮常详细的划分:
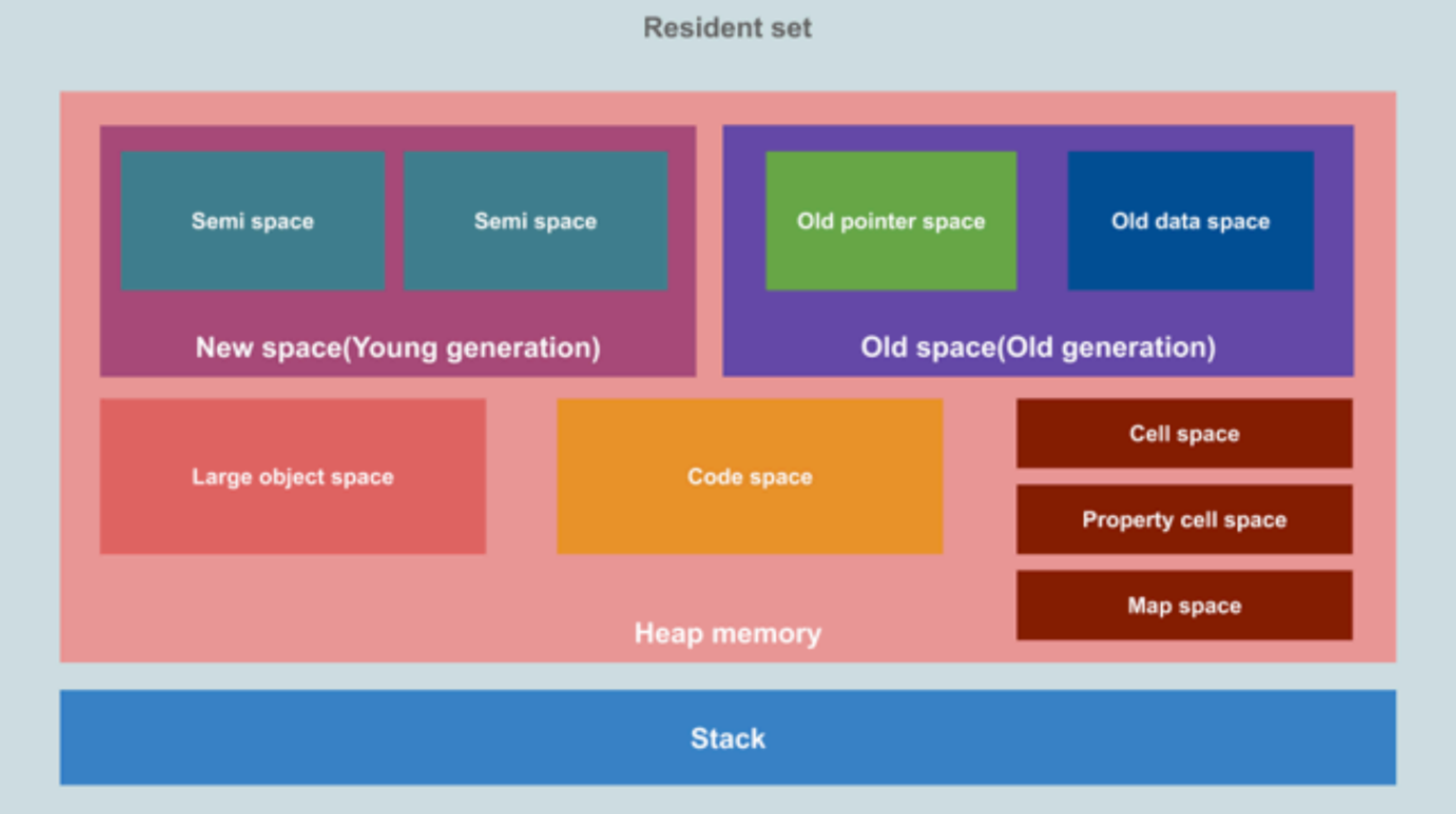
新⽣代空间 (New Space / Young Generation)
作⽤:主要⽤于存放⽣命周期短的⼩对象。这部分空间较⼩,但对象的创建和销毁都⾮常频繁。
组成:新⽣代内存被分为两个半空间:From Space 和 To Space。
初始时,对象被分配到 From Space 中。
使⽤复制算法(Copying Garbage Collection)进⾏垃圾回收。
当进⾏垃圾回收时,活动的对象(即仍然被引⽤的对象)被复制到 To Space 中,⽽⾮活动的对象(不再被引⽤的对象)被丢弃。
完成复制后,From Space 和 To Space 的⻆⾊互换,新的对象将分配到新的 From Space 中,原 ToSpace 成为新的 From Space。
⽼⽣代空间 (Old Space / Old Generation)
作⽤:存放⽣命周期⻓或从新⽣代晋升过来的对象。
当对象在新⽣代中经历了⼀定数量的垃圾回收周期后(通常是⼀到两次),且仍然存活,它们被认为是⽣命周期较⻓的对象。
分为三个主要区域:
⽼指针空间 (Old Pointer Space):主要存放包含指向其他对象的指针的对象。
⽼数据空间 (Old Data Space):⽤于存放只包含原始数据(如数值、字符串)的对象,不含指向其他对象的指针。
⼤对象空间 (Large Object Space):⽤于存放⼤对象,如超过新⽣代⼤⼩限制的数组或对象。
这些对象直接在⼤对象空间中分配,避免在新⽣代和⽼⽣代之间的复制操作。
代码空间 (Code Space) :存放编译后的函数代码。
单元空间 (Cell Space):⽤于存放⼩的数据结构如闭包的变量环境。
属性单元空间 (Property Cell Space):存放对象的属性值
主要针对全局变量或者属性值,对于访问频繁的全局变量或者属性值来说,V8在这⾥存储是为了提⾼它的访问效率。
映射空间 (Map Space):存放对象的映射(即对象的类型信息,描述对象的结构)。
当你定义⼀个 Person 构造函数时,可以通过它创建出来person1和person2。
这些实例(person1 和 person2)本身存储在堆内存的相应空间中,具体是新⽣代还是⽼⽣代取决于它们的⽣命周期和⼤⼩。
每个实例都会持有⼀个指向其映射的指针,这个映射指明了如何访问 name 和 age 属性(⽬的是访问属性效果变⾼)。
堆内存 (Heap Memory) 与 栈 (Stack)
堆内存:JavaScript 对象、字符串等数据存放的区域,按照上述分类进⾏管理。
栈:⽤于存放执⾏上下⽂中的变量、函数调⽤的返回地址(继续执⾏哪⾥的代码)等,栈有助于跟踪函数调⽤的顺序和局部变量。
一些题目:
什么是垃圾回收机制?并且它是如何在现代编程语⾔中管理内存的?
虽然随着硬件的发展,⽬前计算机的内存已经⾜够⼤,但是随着任务的增多依然可能会⾯临内存紧缺的问题,因此管理内存依然⾮常重要。(前提)
垃圾回收(Garbage Collection, GC)是⾃动内存管理的⼀种机制,它帮助程序⾃动释放不再使⽤的内存。在不需要⼿动释放内存的现代编程语⾔中,垃圾回收机制扮演着⾮常重要的⻆⾊,通过⾃动识别和清除“垃圾”数据来防⽌内存泄漏,从⽽管理内存资源。(作⽤)
在运⾏时,垃圾回收机制主要通过追踪每个对象的⽣命周期来⼯作。(原理)
对象通常在它们不再被程序的任何部分引⽤时被视为垃圾。
⼀旦这些对象被识别,垃圾回收器将⾃动回收它们占⽤的内存空间,使这部分内存可以重新被分配和使⽤。
垃圾回收机制有⼏种不同的实现⽅法,最常⻅的包括(实现,可以先回答⼏种,表示你对GC的理解,等下再回答
V8的内容):
引⽤计数:每个对象都有⼀个与之关联的计数器,记录引⽤该对象的次数。当引⽤计数变为零时,意味着没有任何引⽤指向该对象,因此可以安全地回收其内存。
标记-清除:这种⽅法通过从根对象集合开始,标记所有可达的对象。所有未被标记的对象都被视为垃圾,并将被清除。
标记-整理:与标记-清除相似,但在清除阶段,它还会移动存活的对象,以减少内存碎⽚。
V8引擎的垃圾回收机制具体是如何⼯作的?
V8引擎使⽤了⼀种⾼度优化的垃圾回收机制来管理内存采⽤了标记-清除、标记整理,同时⼜结合了多种策略来实现⾼效的内存管理,包括结合了分代回收(Generational Collection)和增量回收(Incremental Collection)等多种策略。
分代回收:V8将对象分为“新⽣代”和“⽼⽣代”。新⽣代存放⽣命周期短的⼩对象,使⽤⾼效的复制式垃圾回收算法;⽽⽼⽣代存放⽣命周期⻓或从新⽣代晋升⽽来的对象,使⽤标记-清除或标记-整理算法。这种分代策略减少了垃圾回收的总体开销,尤其是针对短命对象的快速回收。
增量回收:为了减少垃圾回收过程中的停顿时间,V8实现了增量回收。这意味着垃圾回收过程被分解为许多⼩步骤,这些⼩步骤穿插在应⽤程序的执⾏过程中进⾏。这有助于避免⻓时间的停顿,改善了应⽤程序的响应性和性能。
延迟清理和空闲时间收集:V8还尝试在CPU空闲时进⾏垃圾回收,以进⼀步减少对程序执⾏的影响。
这些技术的结合使得V8能够在执⾏JavaScript代码时有效地管理内存,同时最⼩化垃圾回收对性能的影响。
JavaScript有哪些操作可能引起内存泄漏?如何在开发中避免?
在 JavaScript 中,内存泄漏通常是指程序中已经不再需要使⽤的内存,由于某些原因未被垃圾回收器回收,从⽽导
致可⽤内存逐渐减少。
这些内存泄漏通常是由不当的编程实践引起的,常⻅的引起内存泄漏的操作有如下情况:
全局变量滥⽤:创建的全局变量(例如,忘记使⽤ var , let , 或 const 声明变量)可能会导致这些变量不被回收。
未清理的定时器和回调函数:⽐如使⽤ setInterval 在不适⽤时没有及时清除,阻⽌它们被回收。
闭包:闭包可以维持对外部函数作⽤域的引⽤,如果这些闭包⼀直存活,它们引⽤的外部作⽤域(及其变量)也⽆法被回收。
DOM 引⽤:JavaScript 对象持有已从 DOM 中删除的元素的引⽤,这会阻⽌这些 DOM 元素的内存被释放。
监听器的回调:在使⽤完毕后没有从 DOM 元素上移除事件监听器,这可能导致内存泄漏。
开发中如何避免呢?重要的是平时在开发中就要尽量按照规范来编写代码。
使⽤局部变量:尽量使⽤局部变量,避免⽆限制地使⽤全局变量。
及时清理:使⽤ clearInterval 或 clearTimeout 取消不再需要的定时器。
优化闭包的使⽤:理解闭包和它们的⼯作⽅式。只保留必要的数据在闭包中,避免循环引⽤。
谨慎操作 DOM 引⽤:当从 DOM 中移除元素时,确保删除所有相关的 JavaScript 引⽤。包括DOM元素监听器的移除。
⼯具和检测:利⽤浏览器的开发者⼯具进⾏性能分析和内存分析。
代码审查:定期进⾏代码审查,关注那些可能导致内存泄漏的编程实践,⽐如对全局变量的使⽤、事件监听器的添加与移除等。
JS代码在内存中的运行原理,作用域链是怎么产生的
基于ES3文档:
首先,JS引擎会在执行任何代码之前,在堆内存中创建一个全局对象(GO),所有作用域都可以访问该对象,里面包含Date、Array、Number、setTimeout等等,其中还有一个window属性指向自己。
js引擎会创建执行上下文(Execution Contexts)。
js引擎内部有一个执行上下文栈(EC Stack)也可称调用栈。
现在他要执行的就是全局代码块,它会先创建一个全局执行上下文(GEC),GEC被放入到ECS中。
准备执行时包含两部分内容:
第一部分,在代码执行前,在parser转成AST的过程中,会将全局定义的变量、函数等加入到GO中,但并不会赋值,这个过程就叫做变量作用域提升。
第二部分,在代码执行中,对变量赋值,或执行其他函数。
注:扫描到函数时,会在堆中创建这个函数对象,它的内存地址被保存在GO中,此时函数的作用域也被确定(当前所处环境),但不会创建内部函数的对象(如果有。
每一个执行上下文都会关联一个VO(Variable Object,变量对象),变量和函数声明会被添加到这个VO对象中,全局执行上下文中VO=GO
执行上下文有三个重要内容:作用域链、this、VO
执行代码时,遇到函数时,就会为它创建新的执行上下文(FEC)并压入栈。
执行上下文中的VO对应的是在堆中创建一个新的AO(激活对象)对象。
这个AO对象会使用arguments作为初始化,初始值是传入的参数。里面的变量会在执行前变量提升不赋值,随后执行,开始赋值。
注意:此时创建的AO对象是在执行到函数时创建的,和全局代码执行前创建的函数对象不是一个对象。之前函数对象里记录的作用域就会被放到函数执行上下文中的作用域链中。
作用域链是一个对象列表,在代码执行时,优先在自己VO中查找变量。不会先去作用域链上查找。
解释了当一个方法中有某个变量的定义,外面作用域中有同名变量,console.log在函数内定义变量前打印,会打印undefined的原因。
主要作用应该是为了实现闭包。
闭包的记忆性其实就是因为函数对象上的scope作用域记录了它定义时所处的作用域环境,当外层函数执行完毕后并且弹栈,因为内层函数的作用域还记录着外层函数的AO对象,所以外层函数的AO对象不会被销毁。
闭包不是js特有的,不是js初创的。
一个函数和对其周围状态(词法环境)的引用捆绑在一起,这样的组合就是闭包。
也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。
在js中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。
所以,从广义的角度来说,js中的函数+外层作用域都是闭包。从狭义的角度来说,js中的函数,访问了外层作用域的变量,它的组合就是一个闭包。
注:V8引擎的优化:
AO对象不会被销毁时,是否里面所有的属性都不会被释放? 答案:没用到的属性就会被释放
闭包形成之后,函数没有用到的外部作用域的属性就会被销毁。
ES5及以后代码执行发生了一些变化
基本思路相同,只是对于一些词汇的描述发生了改变。执行上下文栈和执行上下文也是相同的
在执行上下文中,以前的全局代码VO(变量对象)对应着GO,现在变成了词法环境(LE),属性、方法存储在由环境记录(ER)对应的对象里面。(用于处理let/const声明的标识符)
【LE -> ER -> 对象中存储属性、方法】
和ER平级的还有一个叫做外部词法环境,作用域链通过它链接,全局的词法环境因为是最顶层作用域了,所以指向null【类似以前的scope】。查找变量时先找词法环境再找变量环境。
和LE平级的变量环境(VE),它也对应一个ER,存放处理var和function声明的标识符。LE和VE处于执行上下文中。
LE和VE对应环境记录(ER),环境记录内又分为声明式环境记录和对象式环境记录。一般声明的变量和方法都在声明式环境记录中。
最新:
ES2023开始又发生了一些变化
执行上下文关联的词法环境和变量环境都是一个环境记录
全局执行上下文关联一个全局环境记录,全局环境记录中包含一个声明环境记录(let/const属性)和一个对象环境记录(window对象/var/function)
函数的执行上下文关联的环境记录中只有一个声明环境记录,和声明环境记录平级的是外部环境记录,存储作用域。
关于重复声明的解释:
一个声明式环境记录如何区分var变量和let/const变量?
CreateMutableBinding:用于创建var变量的可变绑定
CreateImmutableBinding:用于创建let和const变量的不可变绑定
不可变绑定就是说一旦这个名字和变量关联后,它们的绑定关系不可改变
一些题目:
什么是变量提升?
变量提升是javascript中的一个行为,它使得函数声明和变量声明(var声明的变量)在代码执行前被提升到其作用域的顶部。
- 仅仅是声明被提升,赋值仍然会在代码中声明的位置执行。
为什么存在变量提升?
在javascript早期版本中,解释器会通过两个阶段处理代码:编译阶段和执行阶段
在编译阶段,解释器会先读取并处理所有的声明,在执行阶段,才会处理实际的代码。
这种设计使得在同一作用域内的变量和函数可以在声明之前被引用。提供了一定的灵活性。
然而,这也可能导致代码运行结果不直观,这其实是JavaScript早期设计的一种缺陷。因此现代JavaScript(ES6及以后)引入了let和const关键字,这两者不会发生变量声明提升,使代码更加可靠和利于理解。
变量声明提升有哪些潜在的缺点?
变量覆盖问题:在同一作用域内,如果不小心重复声明变量,由于变量声明提升,后面的声明会覆盖前面的声明。
意外行为:可能导致逻辑上的错误
函数声明的混淆:函数提升意味函数声明可以在函数实际定义之前调用。可能导致同名覆盖
可读性和维护性降低:可能导致代码逻辑难以理解。
在JS中有以下几种常见作用域:
1.全局作用域:当变量在代码中的任何函数外部声明时,它就拥有全局作用域。意味着任何代码的任何部分都可以访问这些全局变量,全局作用域的变量在页面关闭前一直存在,过多的全局变量可能导致命名冲突问题。
2.函数作用域:在函数内部声明的变量具有函数作用域,这些变量只能在函数内部被访问,函数的参数也具有函数作用域。
3.块级作用域:使用let和const声明的变量具有块级作用域,这些变量尽在其包含的{}大括号中可被访问。是ES6的新增特性,在循环或者条件语句中很有用
4.模块作用域:在ES6模块中,顶层声明的变量、函数、类等不是全局的,而是模块内部的。这些声明仅在模块内部可用,除非被导出。
作用域链
作用:用于确定当前执行代码的上下文中变量的查找和访问机制
作用域链的构建基于词法作用域的结构,即变量和函数的可见性由它们在代码中的位置决定。
每个执行上下文都关联一个作用域链
作用域链是一个包含多个环境记录的列表
是闭包的核心组成和前提
var、let、const
let、const 不可重复声明
let、const 有块级作用域
let、const 也会变量声明提升,但它有暂时性死区,在作用域内变量没被赋值的时候是禁止访问的,报ReferenceError
const 声明的是常量不可重新赋值